Event ingestion¶
What is event ingestion?¶
Event ingestion can be defined by breaking down the phrase within the context of business modeling. “Events” are things that happen of note. Within metering, events refer to actions related to a customer using the product. “Ingestion” is how those events get captured and stored within the metering system. A high level diagram of how a system like this would work is displayed below.

Why is event ingestion important?¶
At a high level, without a way to capture and store events metering is not possible. From a tactical perspective, ingestion determines the format of the events to be processed. If the format is inflexible, lacking in attributes or difficult to query the rest of the business model can suffer.
How is event ingestion modeled?¶
There are numerous ways to capture events within software. This is such a well traversed space that there’s even an entire software category, customer data platforms , built around it. So, whether you collect the data through a vendor or through a custom in-house solution, it doesn’t matter. As long as the events can be accessed by the business model, metering is possible.
Fundamental structure of an event¶
As mentioned earlier, how the events get logged isn’t important from the perspective of bframe, but what’s captured is. An event should at least have the following attributes:
Unique event identifier (to prevent duplicates)
Customer identifier (to tie to a specific entity)
Event timestamp (to indicate when the event occurred)
Properties for event filtering
This would end up looking something like this when persisted:
transaction_id |
customer_id |
properties |
metered_at |
received_at |
|---|---|---|---|---|
1717190245.0Wasafi_le_photographe.jpg |
Lupe |
{“name”:”update”,”agg_value”:85.0,”category”:”Wiki_Loves_Africa_All_Images”} |
2024-05-31 22:00:00 |
2024-05-31 22:00:00 |
1716979727.0Alex_Bubenheim.png |
Lupe |
{“name”:”update”,”agg_value”:22.0,”category”:”UNESCO”} |
2024-05-29 11:00:00 |
2024-05-29 11:00:00 |
1716974128.0فرحة_الثور_السودانين.jpg |
Lupe |
{“name”:”update”,”agg_value”:17.0,”category”:”Supported_by_Wikimedia_Deutschland”} |
2024-05-29 10:00:00 |
2024-05-29 10:00:00 |
1716894605.0ECDM_20230508_WF_Amazonia_fires.pdf |
Lupe |
{“name”:”update”,”agg_value”:1.0,”category”:”Modern_art”} |
2024-05-28 12:00:00 |
2024-05-28 12:00:00 |
1716893671.0Europe_remains_affected_by_drought_this_Autumn_(Copernicus).jpg |
Lupe |
{“name”:”update”,”agg_value”:38.0,”category”:”Supported_by_Wikimedia_Deutschland”} |
2024-05-28 11:00:00 |
2024-05-28 11:00:00 |
Unique identifier¶
Event identifiers allow for a metering service to avoid double counting usage. Double counting is problematic since the associated line items are wrong. This can lead to incorrect invoices, inaccurate forecasts or a host of other issues. A unique identifier per event allows for the metering service to perform deduplication to prevent this issue. In bframe this identifier is called the transaction_id.
Customer identifier¶
Regardless of the type of application, there is an entity related to the event. This entity is referenced by the customer identifier, customer_id. This identifier can be a natural key or a pseudo foreign key that references the customer model.
Event timestamp¶
Usage, in the context of a business model, is presented within a specific window of time. Placing a timestamp, metered_at, on each event allows a metering service to put each action in the appropriate bucket based on the period.
This field is not to be confused with when an event was received the received_at field represents when the event was ingested. These two fields are separate to allow for operators to create events that occurred in the past, i.e. backdated events. This is useful in the case that a problem has occurred in the system and manual intervention is needed to fix it. In this case an event would be created with a metered_at prior to the received_at. Backdating is most common when updating a line item that might have had missing events.
For example in the data below, an event was received as of 2024-06-01T01:00:00 even though it was metered as of 2024-05-03T21:00:00.
customer_id |
transaction_id |
properties |
metered_at |
received_at |
|---|---|---|---|---|
Lupe |
1714776214.0Weaver_birds_nest_on_an_electric_pole_01.jpg |
{“name”:”update”,”agg_value”:1000.0} |
2024-05-03 21:00:00 |
2024-06-01 01:00:00 |
Event properties¶
At a minimum, calculating usage requires a customer and timeframe. Only the simplest of usage calculations have only these filters. Most usage calculations include more custom logic that is based on the event properties. A less romantic view of this attribute is a junk drawer that is filled with extra information to discern usage. bframe models these properties as a JSON blob with little to no structure required.
Each property has a key and a value which can be referenced when querying usage. Events that are used in the Wikipedia example have a property for the type of event, the size of the file and whether or not it’s a .jpg being updated.
When choosing event properties it can feel a bit overwhelming due to the ambiguity. The rule of thumb is to add more properties than needed since it’s easy to ignore them and remove them going forward. This is in contrast to adding properties after the fact, which is much more challenging. Of course creating extremely large event properties is not advised especially if the scale of events is higher. This type of behavior can lead to challenges in data egress due to the sheer magnitude of data.
Scaling ingestion¶
Modeling a high scale product requires more effort when it comes to event ingestion. If a customer is consuming 100’s or 1000’s of units per second, a metering service might need adjustments to keep up. The most common technique to ease throughput is to employ aggregation. If the end goal is data freshness a tradeoff can be made on the granularity of the events. For example, instead of sending 10 events for one customer just send 1 with all of the required data. This is valuable since this would reduce the throughput to 1/10th of the former. Although the reduction in granularity would lead to all event specific metadata data being lost.
The following is an example where events are being aggregated to reduce the number of events being ingested.
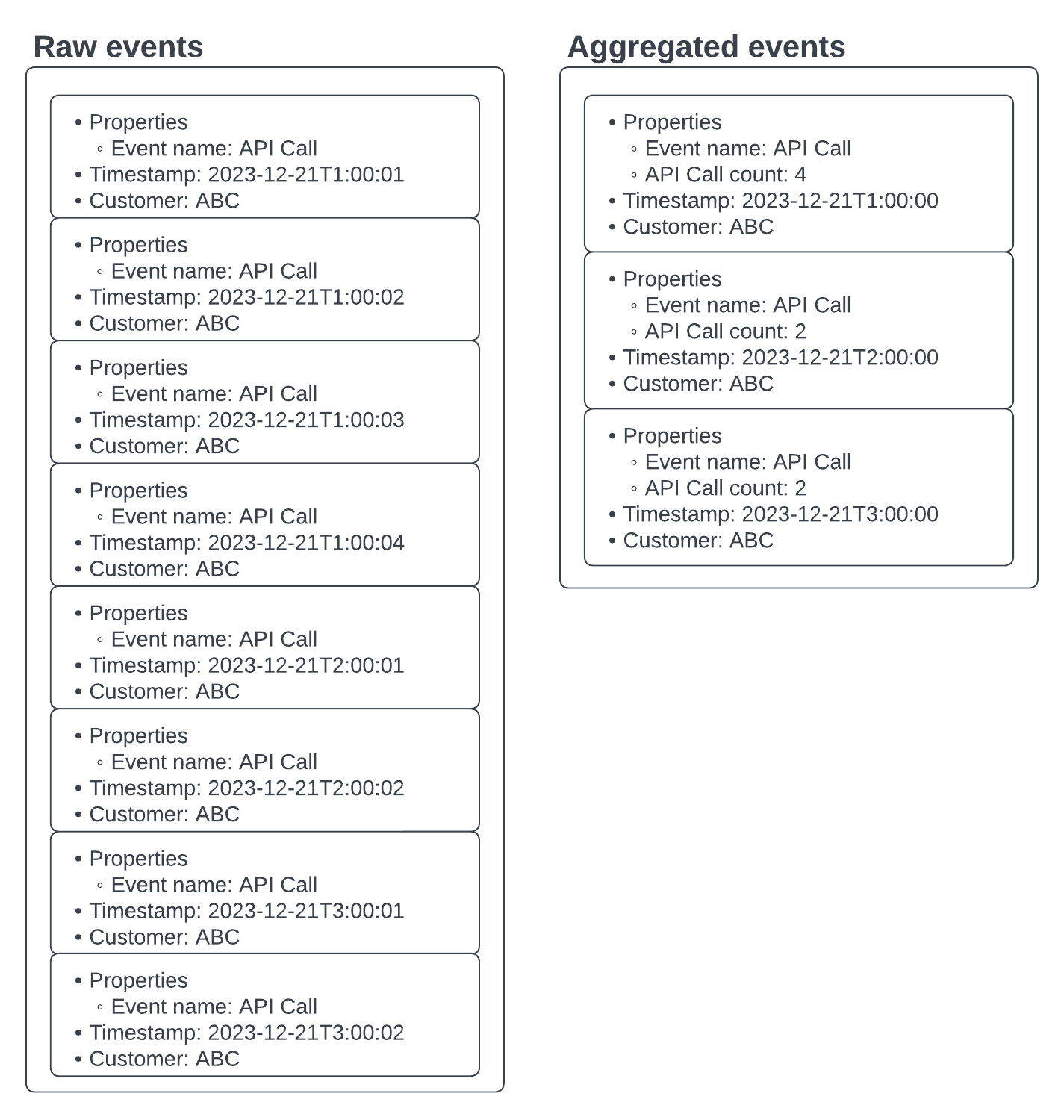
The example shows aggregation at the hourly level, but it can be employed at any time interval. This straightforward technique can reduce the burden of ingestion and other downstream processes. Of course optimizing before hitting a performance bottleneck is not best practice, but the existence of slack in the system is a good thing. While granularity and the visibility it provides are important, uptime and reliability should always be seen as the highest priority.